![[レポート] AWS Lambda and Apache Kafka for real-time data processing applications #SVS321](https://images.ctfassets.net/ct0aopd36mqt/3IQLlbdUkRvu7Q2LupRW2o/edff8982184ea7cc2d5efa2ddd2915f5/reinvent-2024-sessionreport-jp.jpg?w=3840&fm=webp)
[レポート] AWS Lambda and Apache Kafka for real-time data processing applications #SVS321
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは、リテールアプリ共創部のmorimorikochanです。
現地でセッションを受けたので内容をレポートします。
概要
セッションカタログの内容は以下のとおりです。
タイトル
SVS321 | AWS Lambda and Apache Kafka for real-time data processing applications
概要
In this session, gain practical insights into building scalable, serverless data processing applications by integrating AWS Lambda with Apache Kafka. Explore using event-driven models for real-time data streaming and processing. Discover different architectural patterns and best practices to achieve high throughput, fault tolerance, and low latency. Leave with the knowledge to design serverless data processing pipelines that extract valuable insights from real-time data streams efficiently and cost-effectively.
その他
- Session types: Breakout session
- Topic: Serverless Compute & Containers
- Area of interest: Event-Driven Architecture, Lambda-Based Applications
- Level: 300 – Advanced
- Role: Developer / Engineer, IT Professional / Technical Manager, Solution / Systems Architect
- Services: AWS Lambda
内容
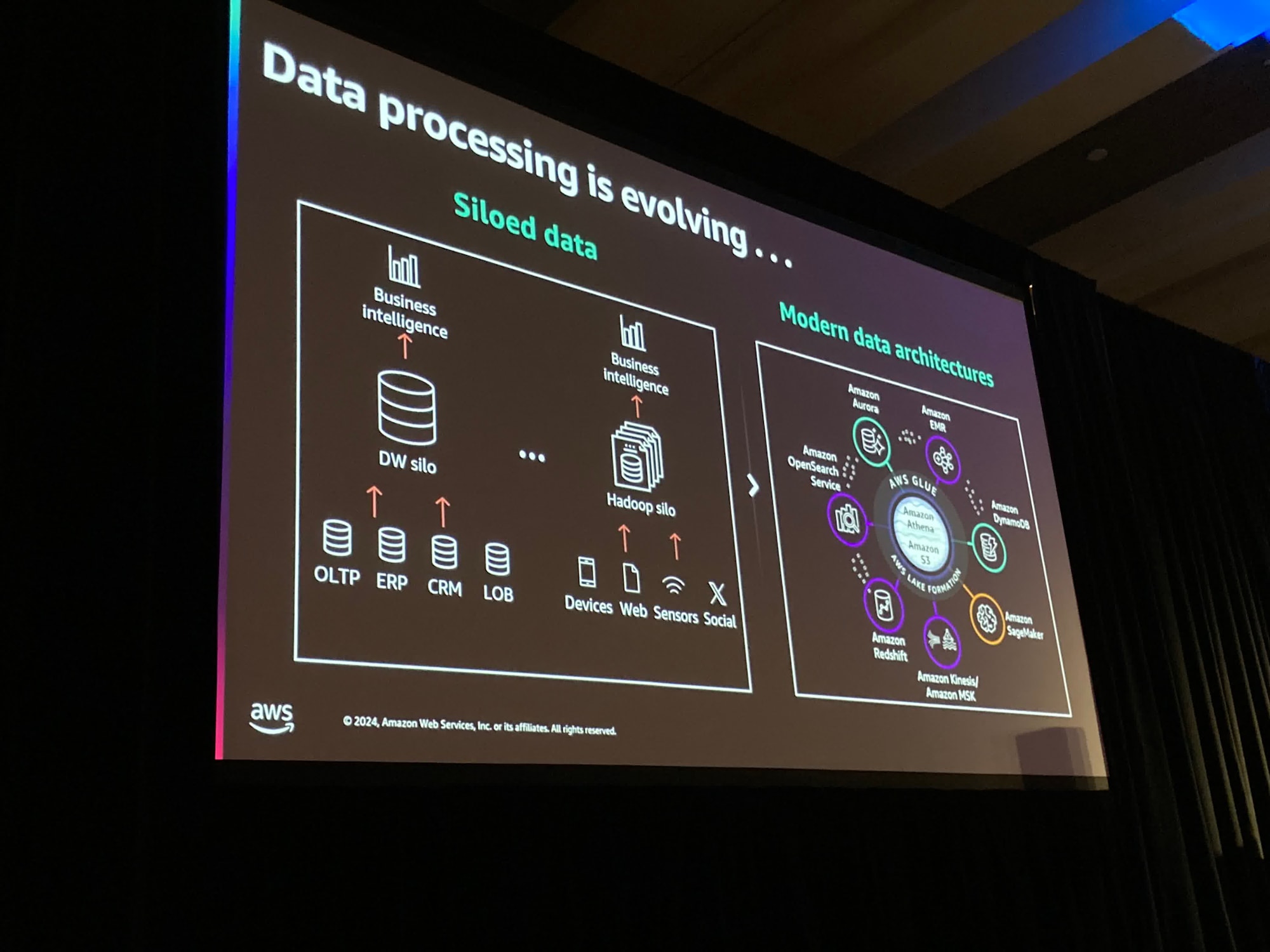
以前はそれぞれがデータに対して異なるユースケースを持っていてデータがサイロ化されていました。
現代では中央にデータレイクとしてのS3を配置しさまざまなサービスが接続されています。また、さらにそのデータに対してさまざまなパターンでアクセスしています。
なので以前よりこれらのデータとの接続性に対してより深い洞察が求められます。

クリックストリームデータを分析している場合、毎日の終わりにデータを処理することはある種の有用性があります。
しかし、リアルタイムでデータを取得することで、より実用的に何をしているか把握し改善し行動を起こすことができるようになります。

さまざまユースケースが世の中に存在している。
もしかするとあなたはオンラインゲームを運営しているかもしれません。
また、IoTもよく知られた例の1つです。
家電製品やどこかに埋め込まれたセンサーからのデータを収集し配置されます。
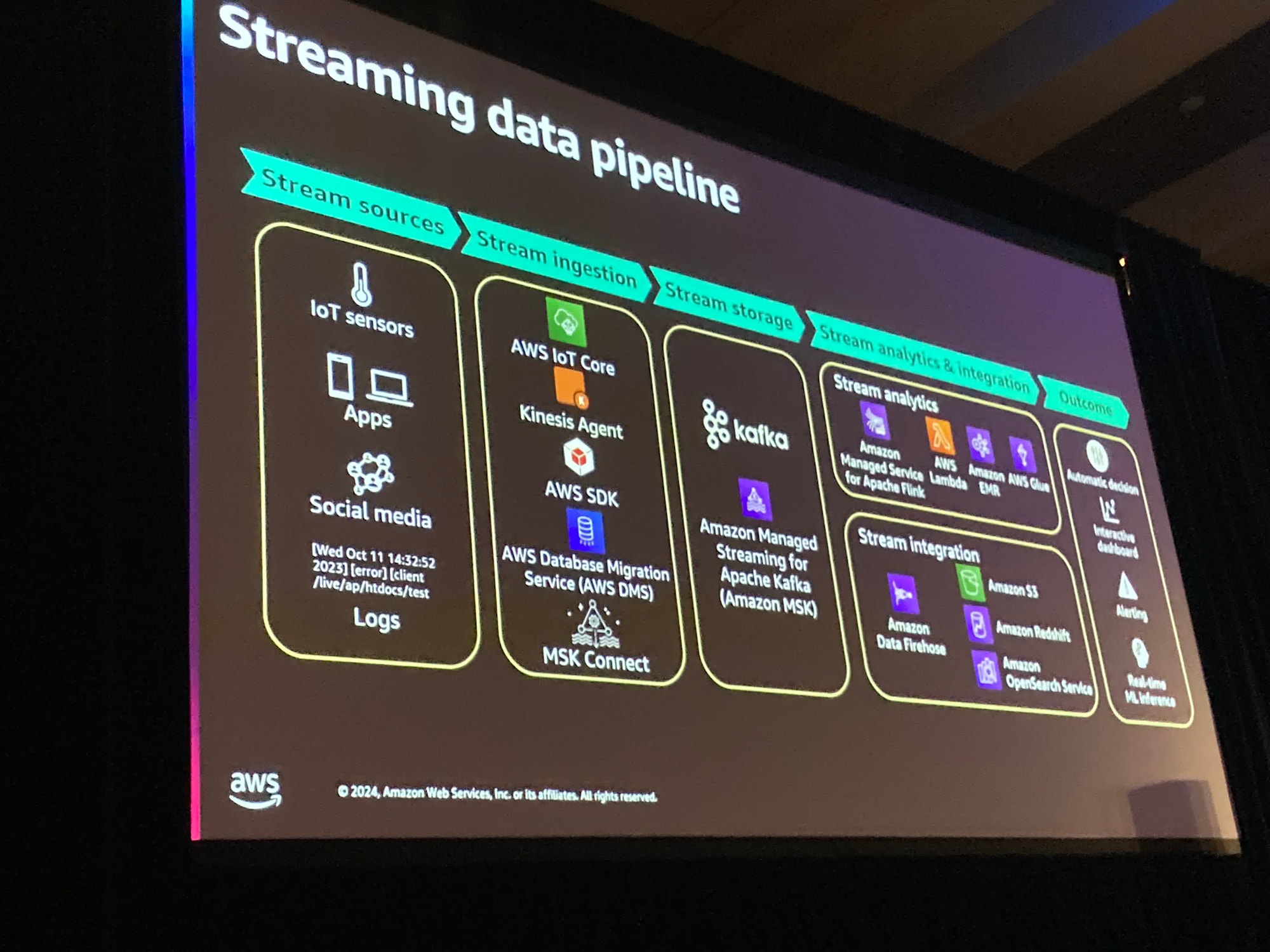
あなたがやりたいことはデータを集約し、別のS3バケットに移動させたりすることかもしれません。
これはパイプラインです。
例えばIoTデバイスの場合、収集されリアルタイムに取り込まれる必要があります。
また、保存された期間中には無限に再生できる必要があります。
これはストリーミングデータが重要である理由です。
また、データを読み込む際に、分割と統合を行います。
これによってレコードは処理される順番で読み込まれます。
分析はデータそのものに対して行われたり何かしらの処理結果である可能性もあります。
別のS3バケットやOpenSearchクラスタや別のアプリケーションのイベントかもしれません
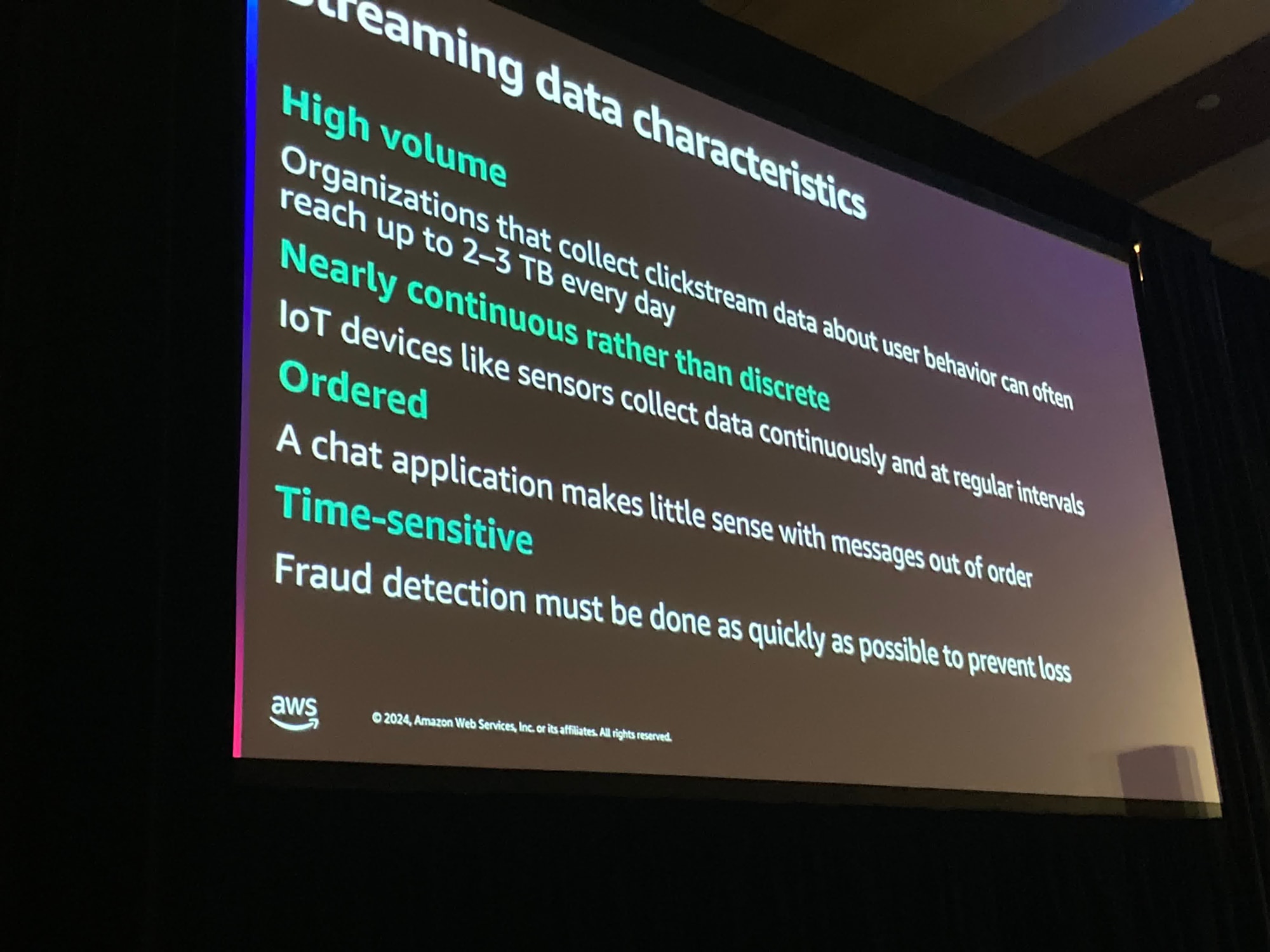
ストリーミングデータは多くの容量を持っています。
人気のwebサイトのクリックストリームデータなどを考えると想像できます。
イベントは数兆にもなるかもしれません
また、これらのデータは連続的であり離散的ではありません。
また、ストリーミングデータはしばしば順序が保たれていす。なぜなら、受信者にメッセージが順序通り届かない場合を想像すると、不自然で意味が通じなくなるからです
また、時間感度が高いという要素もあります。

これからさまざまな用途に対して複数種類の構成を見ていきましょう。まずはAWS上のストリーミングデータから。
Apache Kafkaとはなんでしょうか?
それはStreaming Platformです。

Apache Kafka はいつでもどこでもオンプレミスにインストールすることができます。
あなたのラップトップにもインストールできます。
あなたのデータセンターやその他の場所にも。
また、Amazonは"Amazon MSK"というマネージドサービスを提供しています。
そしてもちろん第三者が素晴らしいサービスを出しています。
Confluentはkafkaを定義する企業の一つです。実際にはkafkaはLinkedInから生まれました。
kafka市場には新しいことを行なっている新たな参入者が存在します。
"Redpanda"や"WarpStream"が挙げられます。これらはkafkaのAPIを提供していますが劇的に簡素化されています。
また、"WarpStream"ははるかに効率的で安価なクラスタを実行できます。

"Amazon MSK"は組織によって安全で高可用性かつアクセス可能なものを提供します。
そして、これによって開発者がインフラに資本を必要とせずアプリケーション開発に集中できるようになります。
既存のアプリケーションやツールがあれば、これらは全て手間をかけずに動作することを意味します。アプリケーションコードの変更は不要です。
またセキュリティは最優先事項です。

私たちは完全に管理されたKafkaを提供しており、他のプロバイダーの1/10のコストだという人もいます。そして、オンプレミスで運用している場合は全てを自分で行う必要があります。ネットワークの設定やレプリケーションなど、運用オーバーヘッドがかかるでしょう。

"Amazon MSK Serverless"は設定や最適化は必要ありません。クラスターを保護したり運用したりアプリケーションをdrainingする必要もありません。
これは素晴らしいことです。リソースを過剰に供給したり過小に供給したりすることを心配する必要もありません。
内部ではジョブを処理しています。利用された分だけお支払いいただきます。また、どのぐらいの期間ストレージを保持するかも考慮する必要があります。
ここから、ストリーミングデータとは一体なんなのか、そしてストリーミングデータのアーキテクチャについて見てみましょう
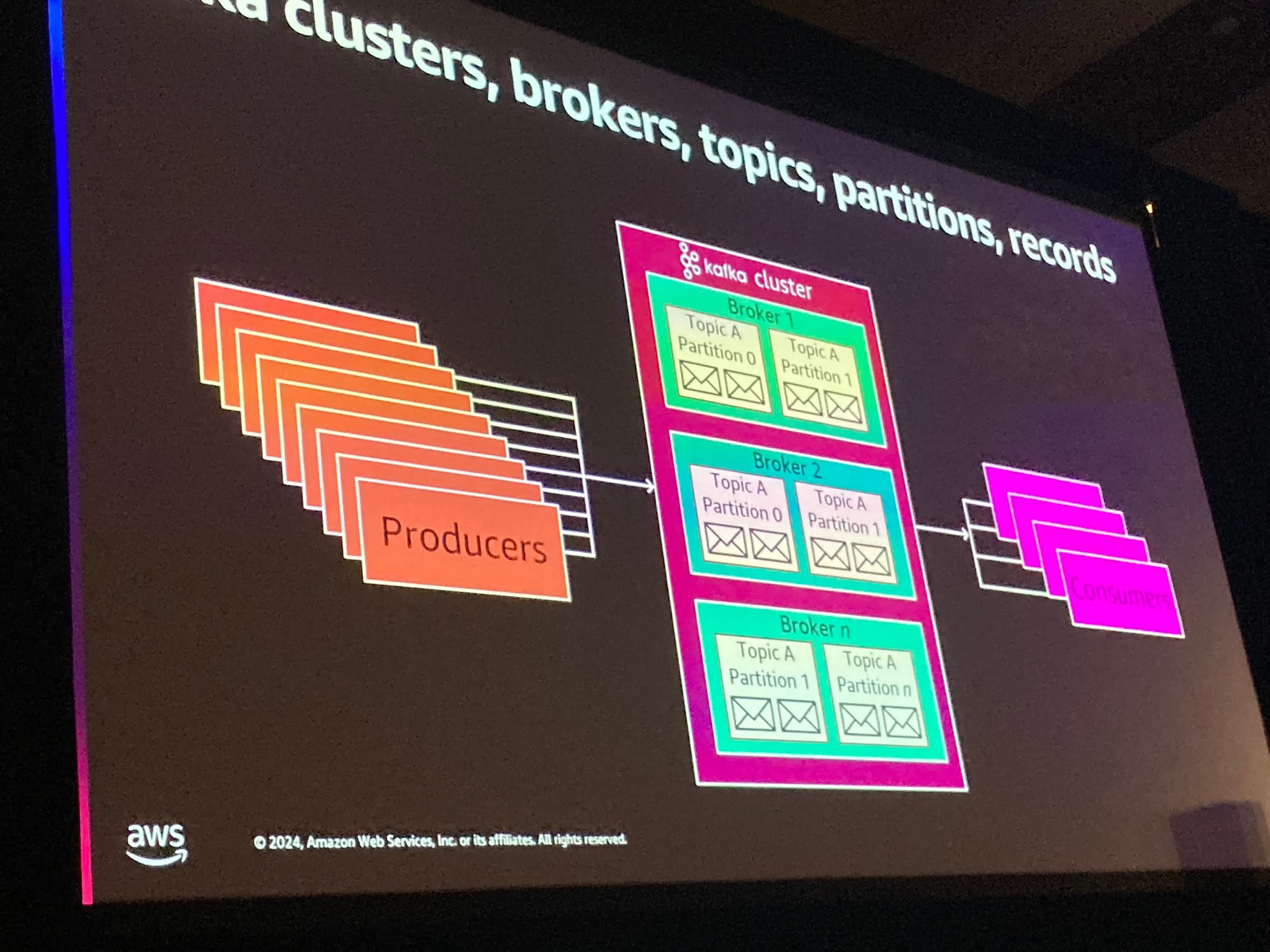
さて、資本の世界では、情報を生産するProucerの概念があります。これはIoTデバイスにもあなたのアプリケーションの一部にもなりえます。
また、他方にConsumer(消費者)も存在します。多くのConsumerがその情報を消費する必要があります。そしてその間にBroker(仲介者)として存在するKafkaがあります。
また、Brokerはカスケードであるため、"Redpanda"や"WarpStream"などの他のものを利用していても同様です。
各ブローカーにはトピックがあります。これは類似のデータを保存するためのメッセージチャネルです。
今あなたの組織には同様のトピックや異なるアプリケーション・異なる部門がそれぞれ独自のトピックを持っているかもしれません。
これはただの論理的な区分に過ぎません
パーティションは異なるブローカーに複製されます。
トピックAはパーティションを2つ持つことでトピックAのスループットを増やすことができます。その後ブローカーに複製されます。
この例では考えられるブローカーが3つあります。
それでは、パーティションの中身を見てみましょう
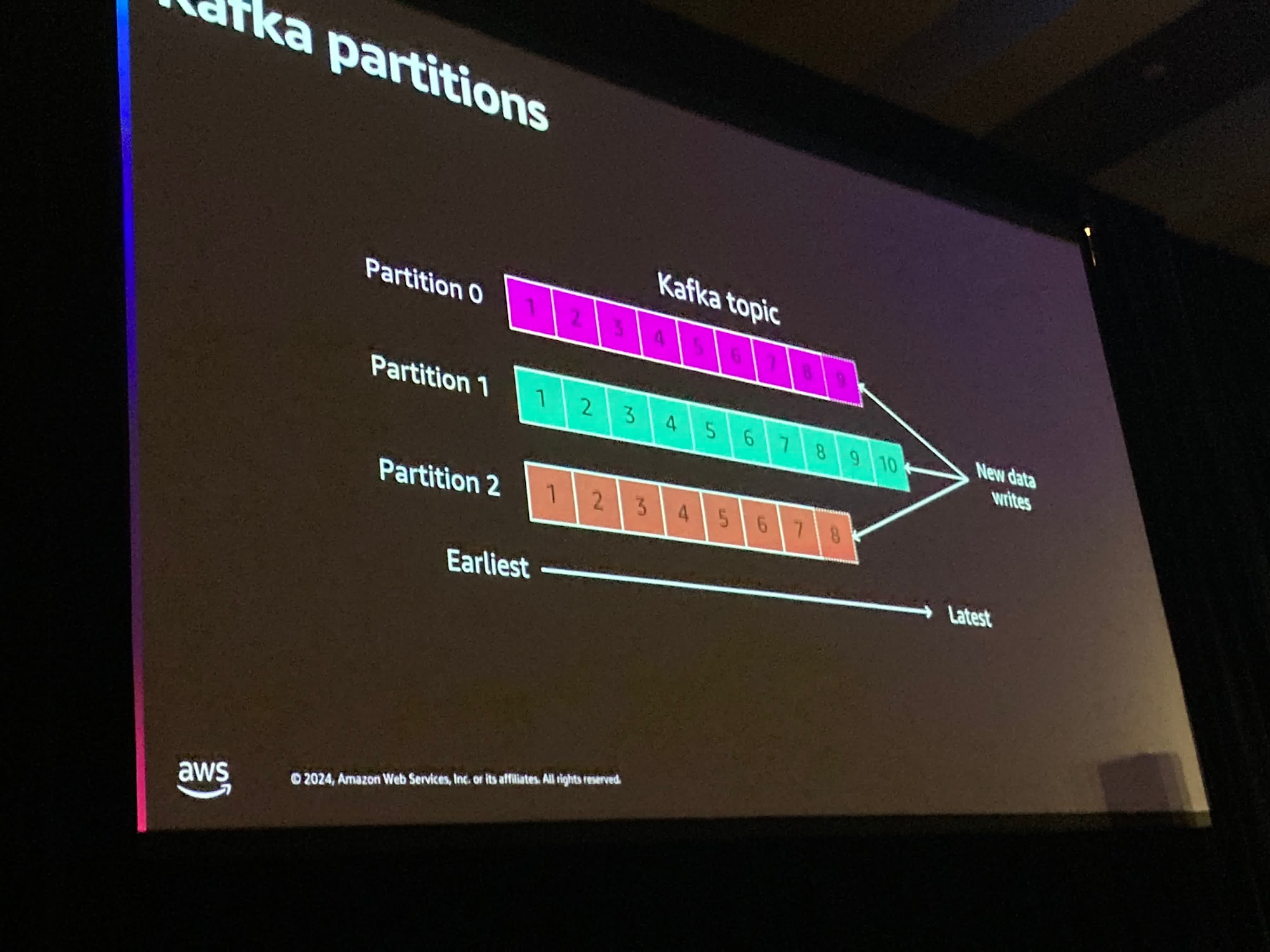
各パーティションにレコードが順番に配置されています。レコードは常に順序通りに存在します。
新しいレコードは前に追加され、その後2つの方法で無効化されます。
1つはストレージによって無効になる方法です。非常に人気があるもう一つの方法は時間によるものです。
1日あるいは1年分のメッセージを保存したい、と伝えることができます。
では、メッセージは特定のパーティションにどのように到達するのでしょうか?
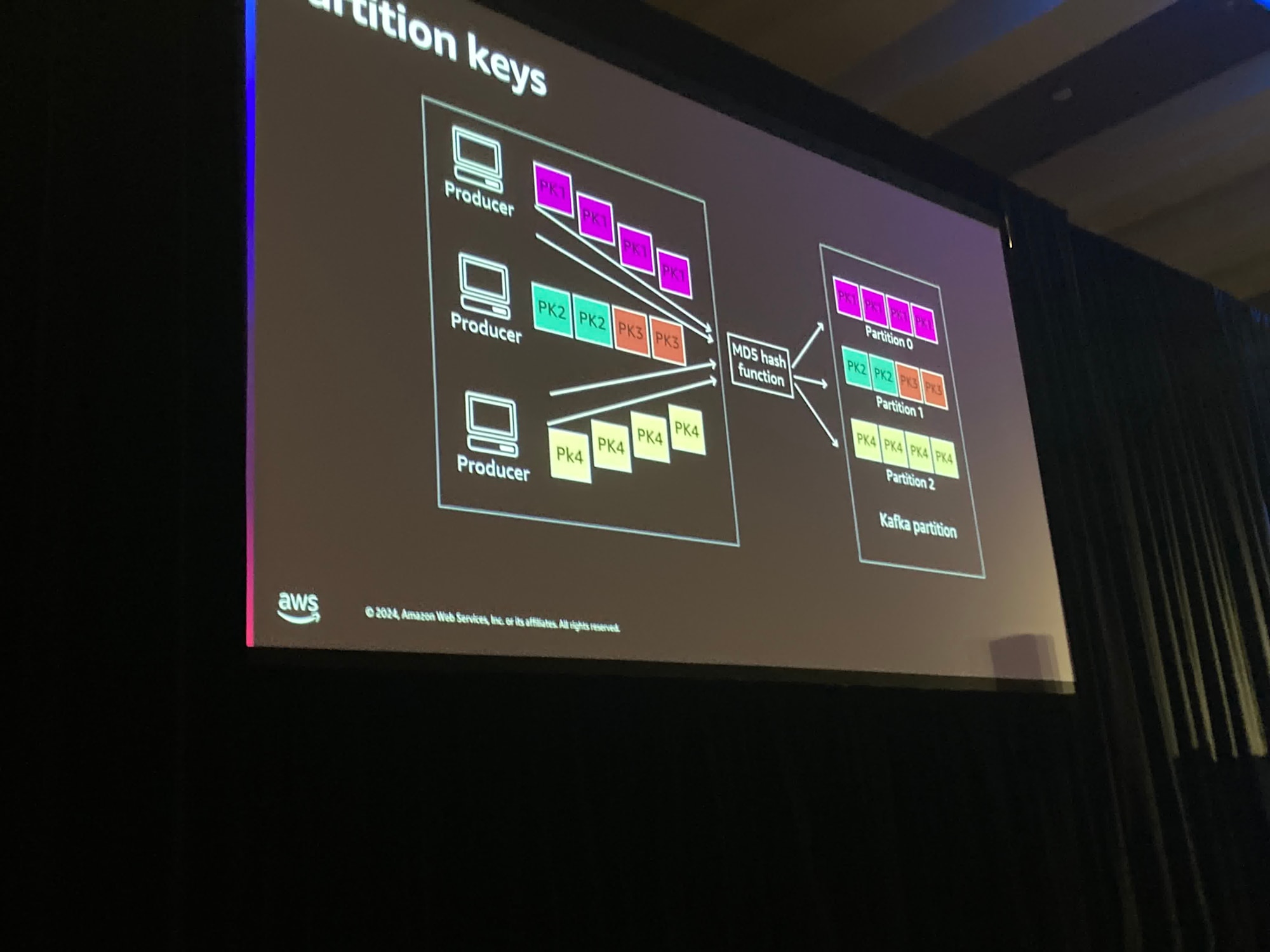
Producerはパーティションキーというものを指定できます。パーティションキーは色々なものになる可能性があり、非常に変動的です。
Kafkaではパーティションキーに対してMD5ハッシュ関数を実行します
ここで見るように、複数のパーティションキーが単一のパーティションに収まる場合もあります。しかし、MD5ハッシュ関数を使用すれば常に同じパーティションに配置されることになります。
これは素晴らしいことで、もし多くのProducerが存在する場合、ポジションの割り当てはどうなりますか?

これはあなたのニーズやアプリケーションによって異なります。ランダムハッシュを利用することもできます。
もしかしたらTime-based hashが必要なのかもしれません。
レコードが同時に到着する場合、同じ時間であったり分単位や時単位で同じであったりするかもしれませんが、とにかくこれを構成することができます。
最終的には同一のタイムスタンプもしくはその一部が利用され同一のハッシュが結果として得られることになります
さらに制御を求める場合があります。アプリケーションに特化した何かを行いたいのです。例えば、ここに顧客IDがありますが、これをキーとして利用します。 これは常にその時テイの顧客に関するレコードが同じパーティションにルーティングされることを意味します。
ただし、スループットとレコードの容量が制限されてしまいます。
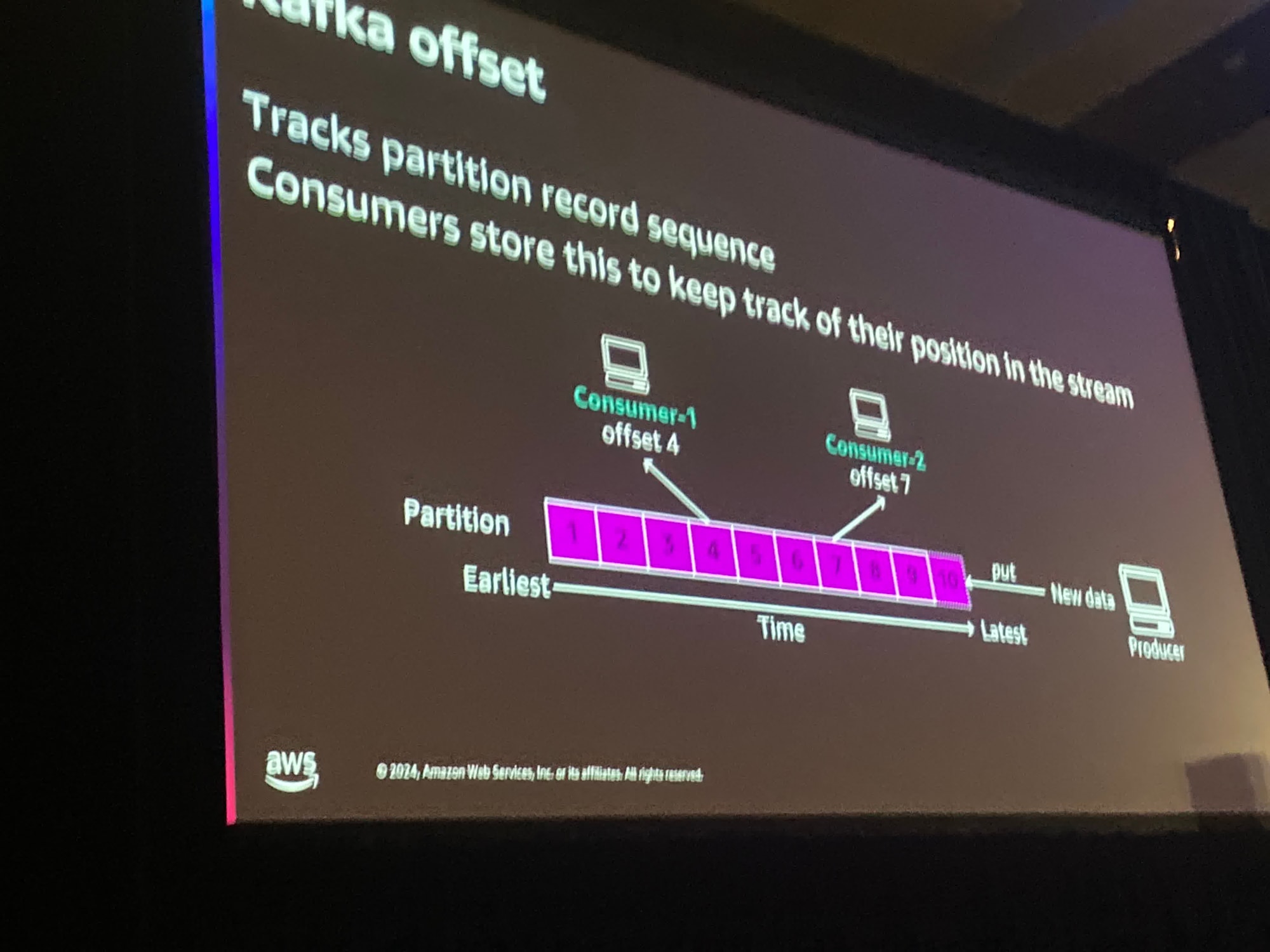
Kafkaにはオフセットの概念があり、オフセット番号があります。これはストリームの位置を示しています。
Consumerが"次のレコードのセットをもらえますか?"というと、"こんにちはCosumer1 あなたはオフセット番号4にいます。次のレコードを5つ渡します。"と言います。

ストリーミングデータの処理に関する、色々な選択肢を見てみましょう。
AWS上では複数の方法があります。
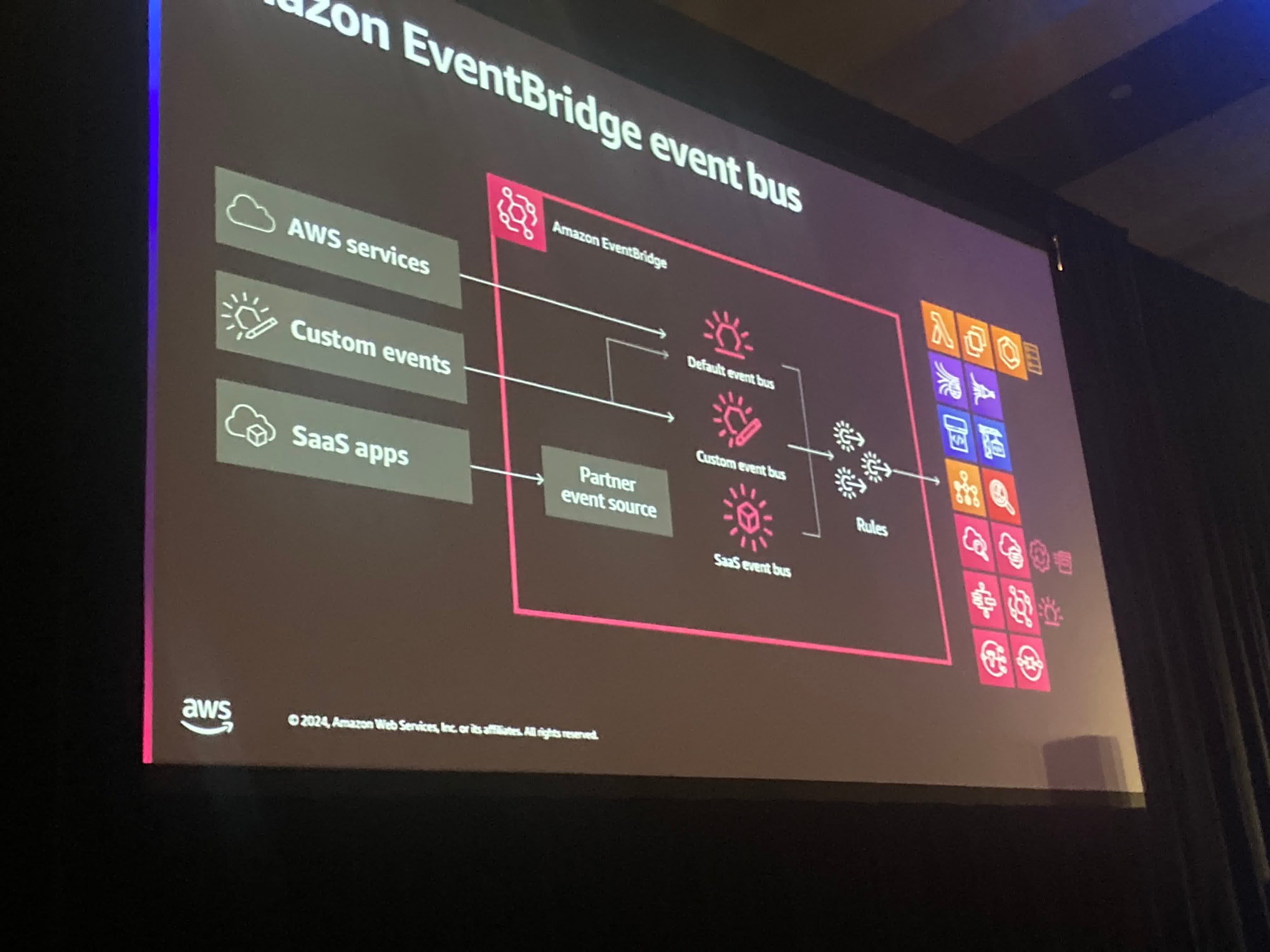
EventBridgeは完全管理型サービスのイベントルーターです。
イベントをターゲットの下流のコンシューマーに接続することができます。
また、多数のSaaSパートナーを接続することができます。

KafkaとEventBridge busは記録を何に使ってどこへ送るかという点で違いがあります。
kafkaの場合はイベントをConsumerが取得します。
EventBridge busはプッシュメカニズムであり、やや異なるモデルです
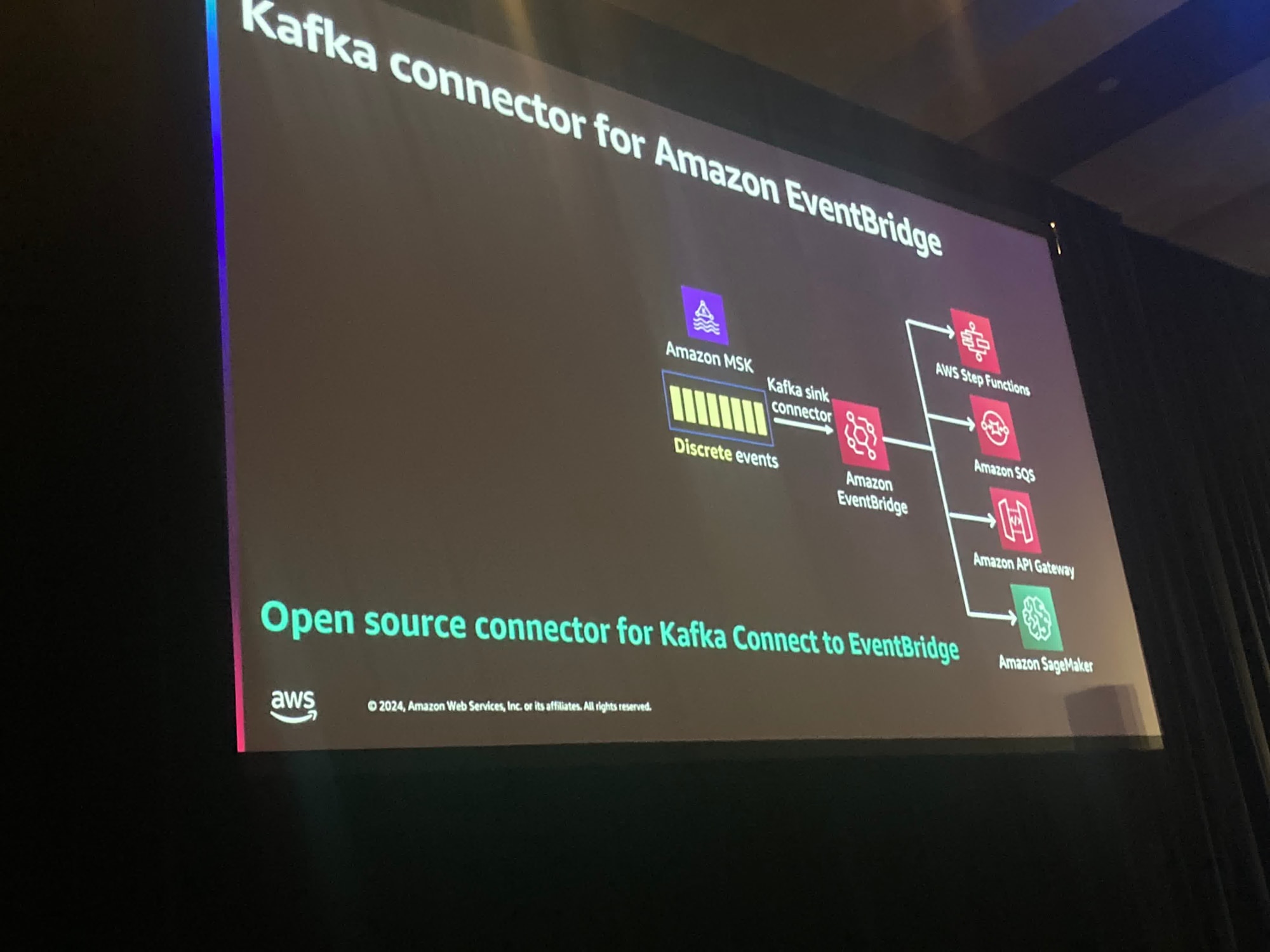
Kafka connector for Amazon EventBridgeがあります。
これは今日のセッションが取り上げたい内容です。
Kafkaを使ってイベントをキャプチャし、Amazon EventBridgeにメッセージをプッシュすることができます。
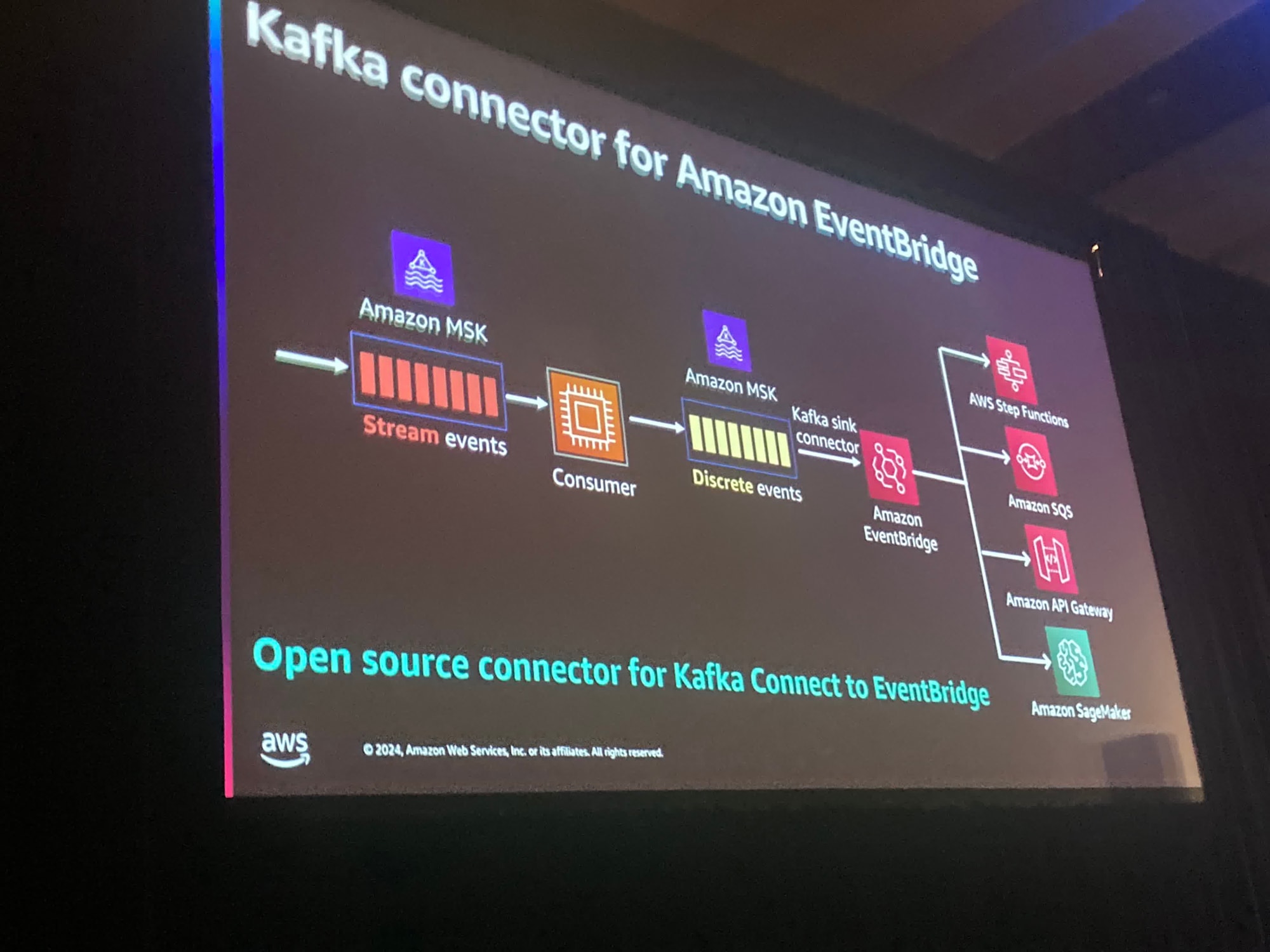
また、個別のデータを管理するのにも役立ちます。
そして、EventBridgeはサーバーレスであるため、サーバーレスであるため、使用する分だけの料金を支払うだけで済みます。
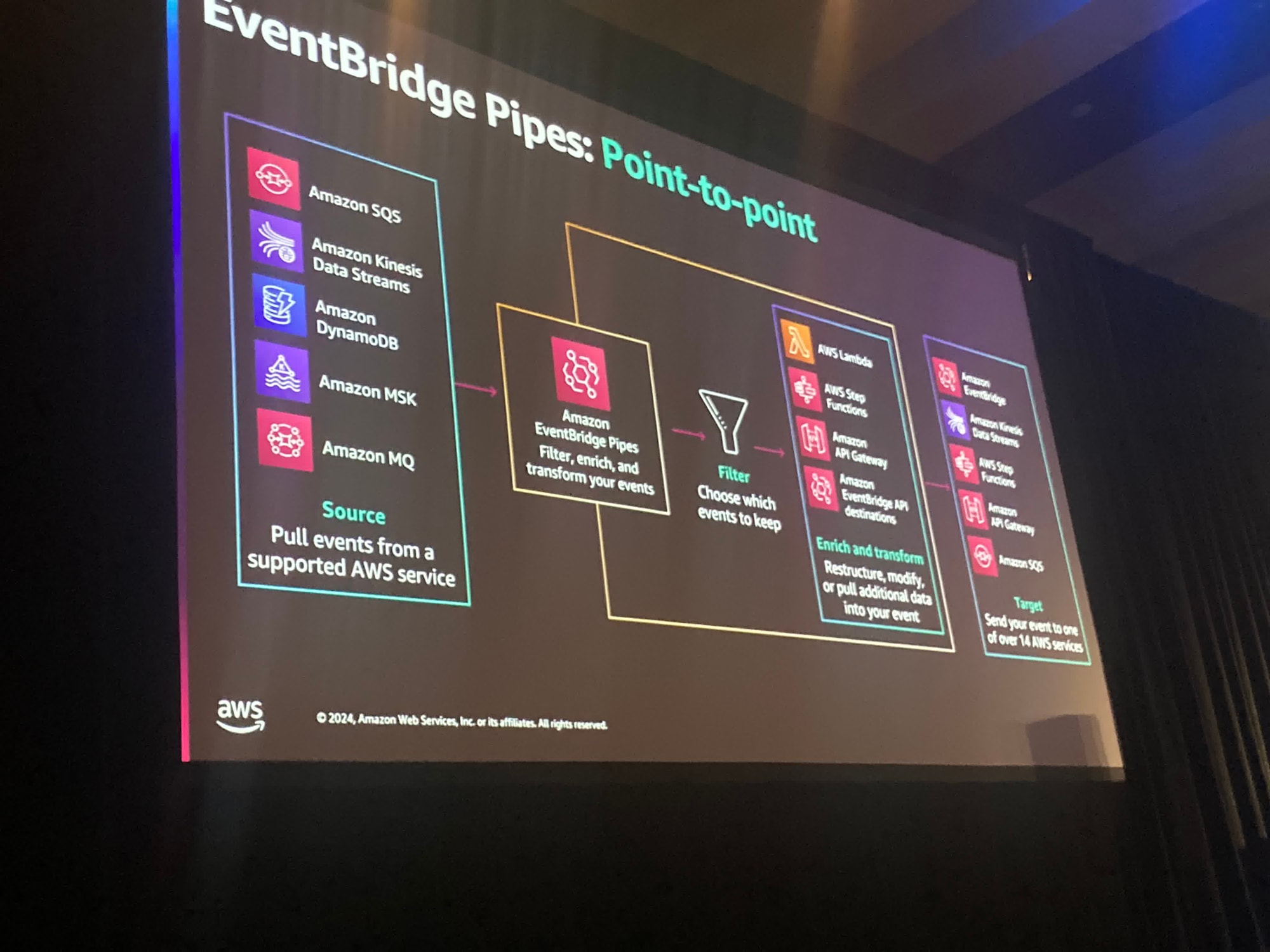
次にEventBridge Pipesという別の種類のEventBridgeがあります。これは実際にはポイント二ポイントアプリケーションを作成するための、より均等に管理された方法といえます。
EventBridge PipesとEventBridgeのどちらもフィルタリングやバッチ処理を行い多くのAWSサービスに送信が可能です

Kafkaクラスタを利用するためには2つの選択肢があります。1つはKafka sink connectorのように間に同期コネクタを作成する方法 ともう一つの方法はLambdaEventSourceMappingを利用することです。
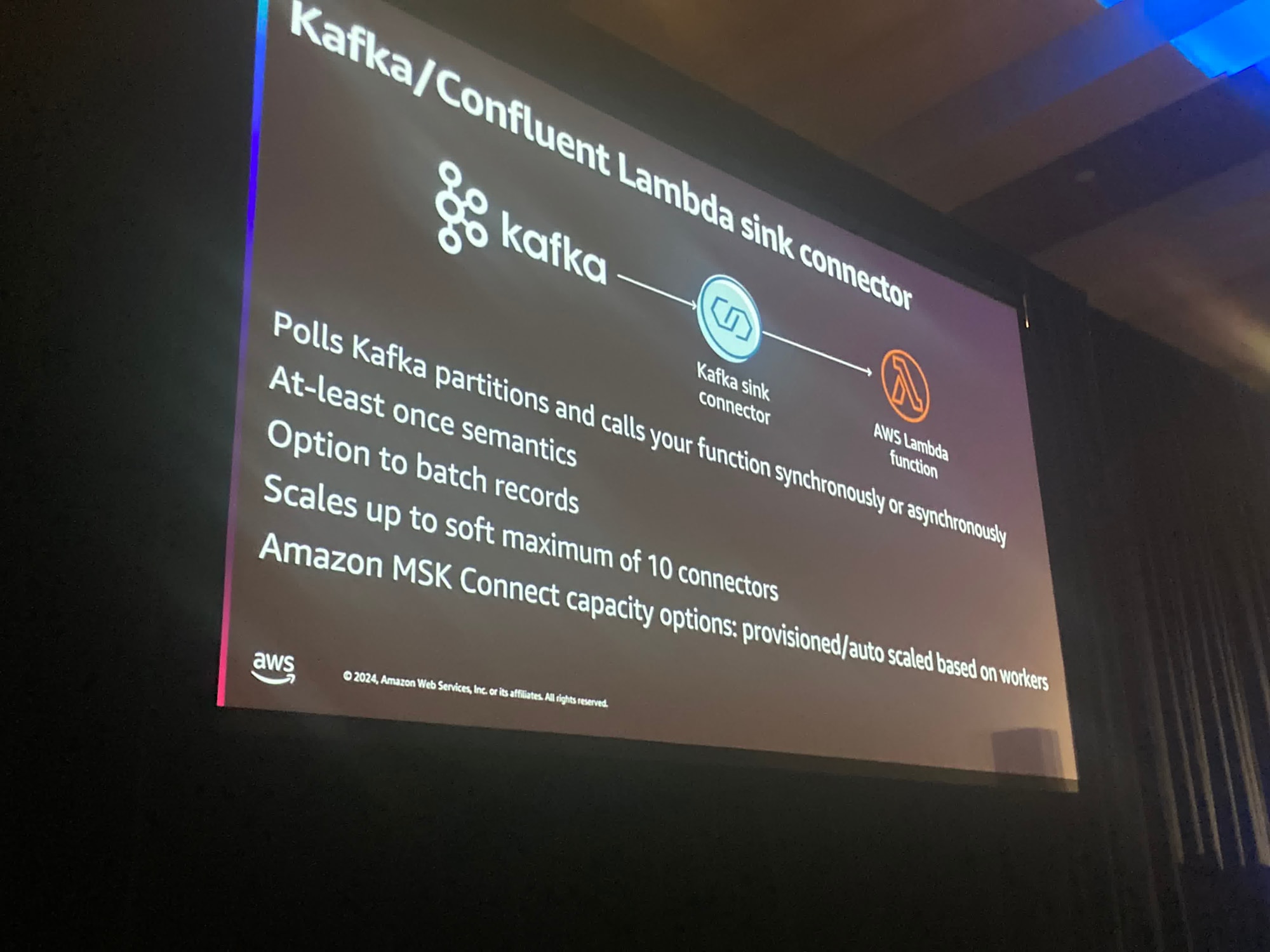
Kafka sink connectorがKafkaのパーティションをポーリングし、Lambda関数を同期もしくは非同期で呼び出します

Lambdaでエラーが発生した際には、ConnectorがDLQにメッセージを転送することができます。
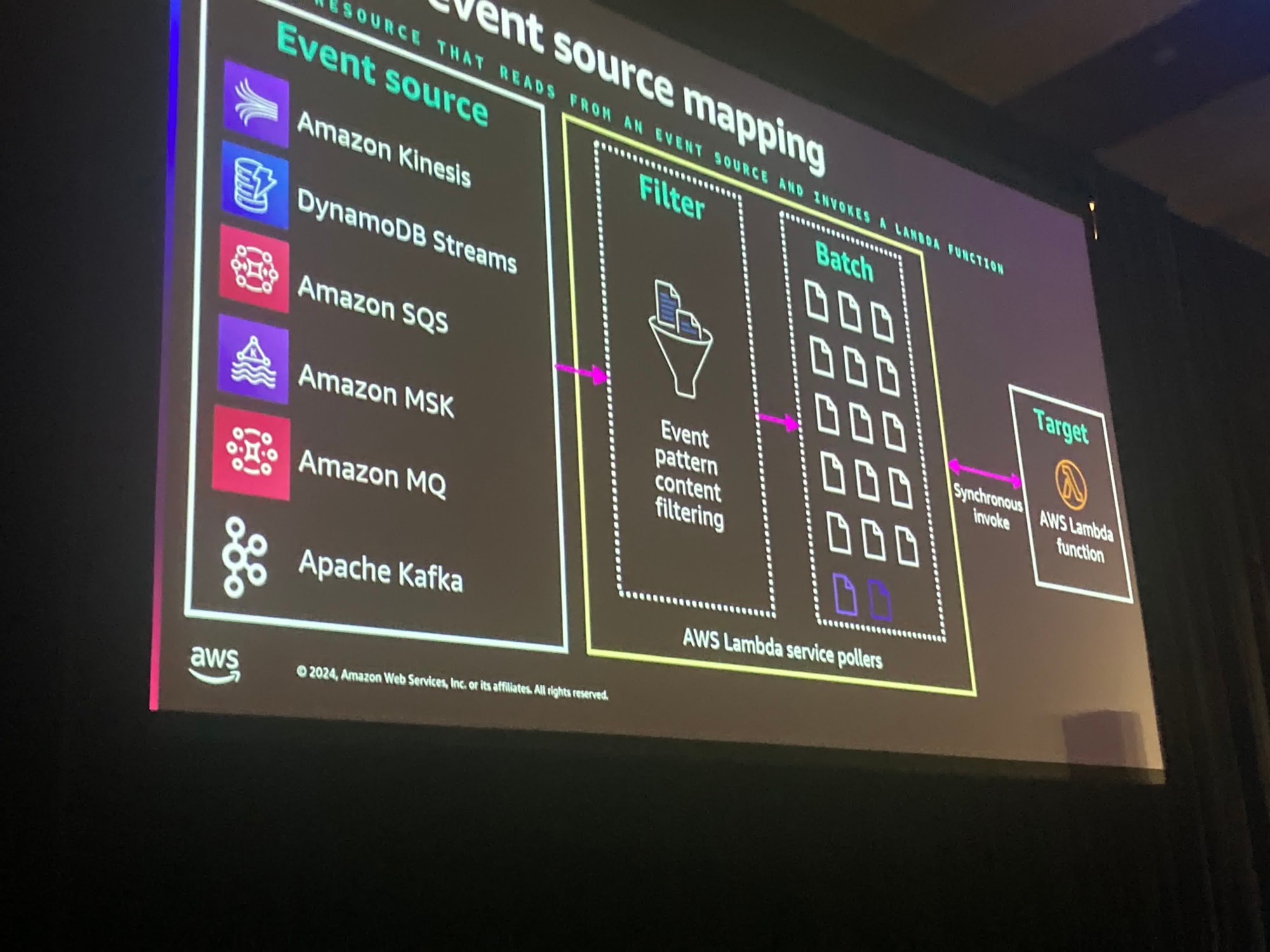
イベントソースマッピングは、さまざまなサービスの集まりから名付けられたポーリングサービスです。これらはオプションでフィルタリングが可能であり、バッチ処理して最終的にあなたのLambda関数を呼び出すことが可能です。

前述の通り、イベントソースマッピングがポーラーの代わりになるため、ポーラーのコードを管理する必要がありません。
また、Lambda側がオフセットの管理を担当しているため、あなたが必要とするのはビジネスロジックを書くことだけです。そして、素晴らしいことにほとんどのシナリオではこれは無料です

ボックスの中身の全てが無料です。
Lambdaはネイティブにいくつかのランタイムをサポートしており、カスタムランタイムも実行できます。これにより、言語に依存しない環境が実現します。
特にKafkaの世界では、様魔座なチームがそれぞれ異なるConsumerを持つことができます。

イベントソースでは、Lambdaの記録の開始点を設定することができます。
ストリーム内の最も古いレコードから読み取ることや特定のタイムスタンプから読み始めることもできます。

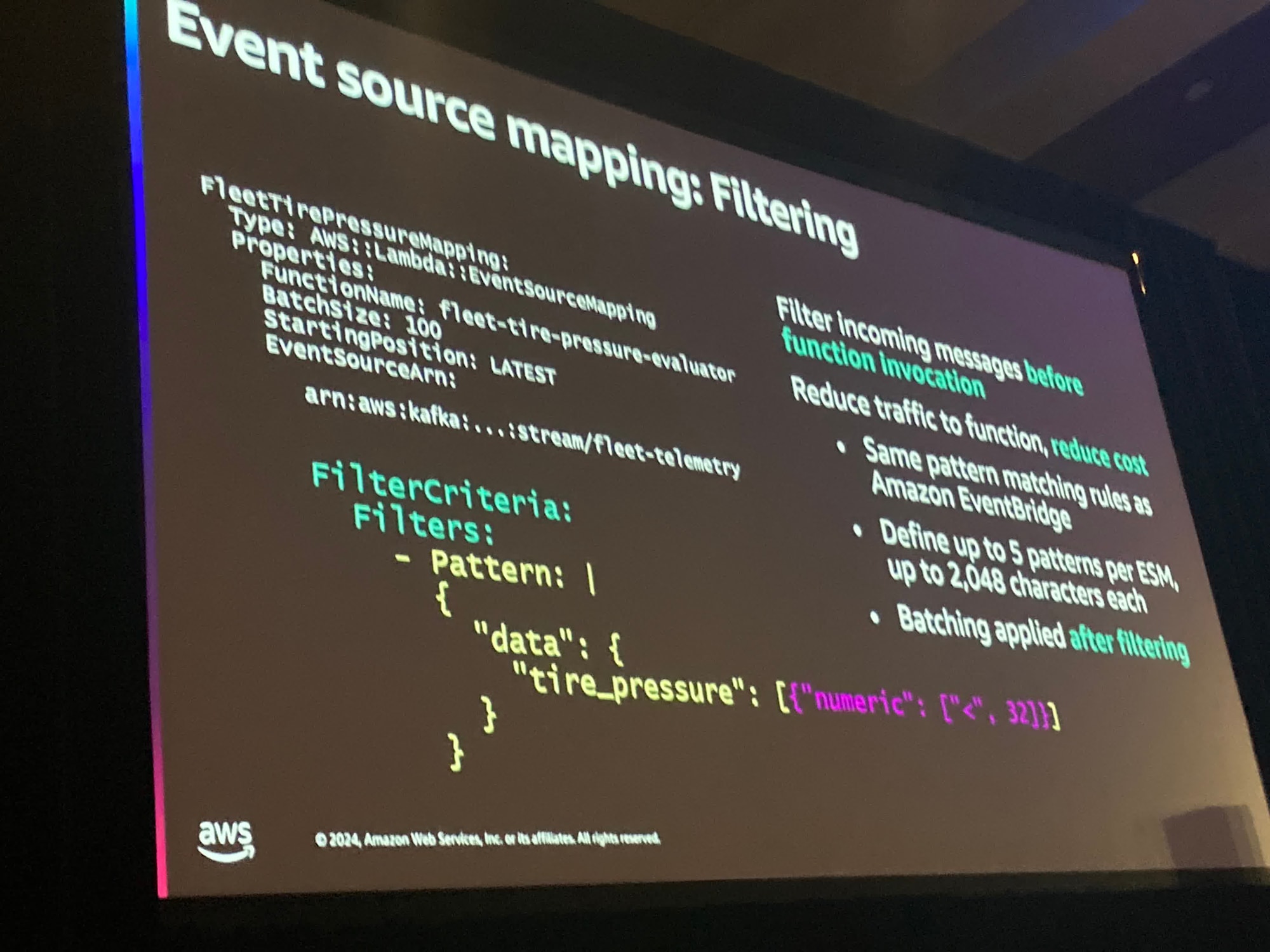
タイヤの空気圧が32未満であるメッセージ。
また、より柔軟により大きな、または小さな、そして膨大な組み合わせの例を行うことができます。

どのようにしてバッチを定義しているでしょうか?
バッチは3つの異なる設定の組み合わせによって決まります。
Batching windowはバッチを充填するために待つ時間の最大値です。 したがって、5分に設定されている場合、最大5分間待ちます
また、バッチのサイズも設定できます。1件のレコードを取得するか、時間をかけて最大1万件のレコードを持つことができます。
10000件のレコードが利用可能になった場合そのバッチを取得してLambda関数に送信します。
最後のポイントはペイロードのサイズの制限です。Lambdaの呼び出しペイロードの制限は6MBです

このシナリオでは40秒が経過し、Batching windowに到達し5レコードがLambda関数に送られます。
(この部分のスライドの写真撮影漏れていました)
第二のシナリオではBatching windowに到達する前に10の利用可能なレコードがあり、これがバッチサイズとして構成されているケースです。
したがって、10のレコードがLambdaに送信されることになります
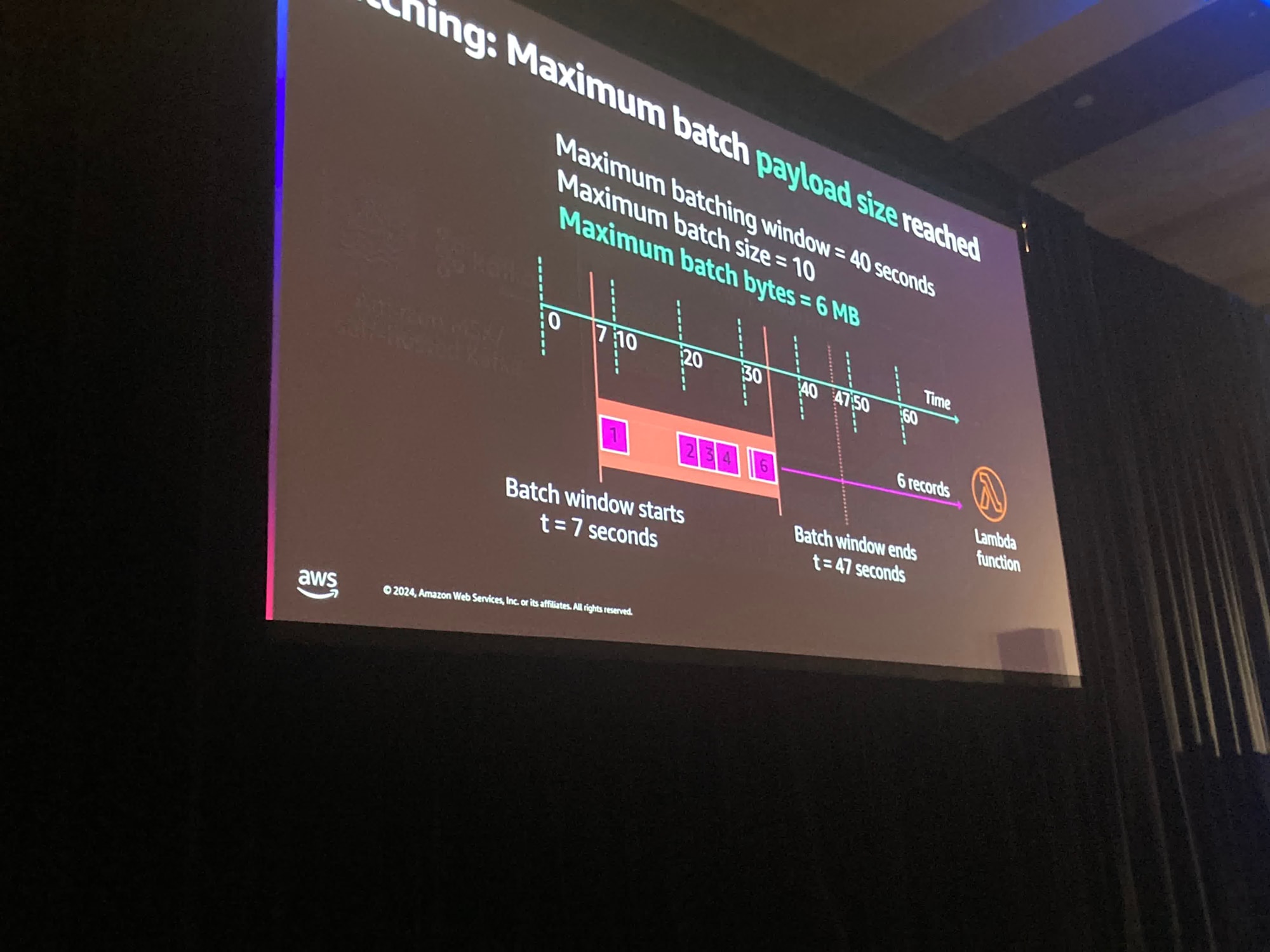
第三のシナリオではBatching windowがリリースされる前にペイロードが6メガバイトに達しました。この一連の記録のバッチが同時に送信されます。

認証オプションを見てみましょう
SASLはkafkaにとって非常に一般的なアプリケーションオプションです。基本的にユーザー名とパスワードを管理し、これを保存するための非常に良い場所はAWS Secrets Managerです。
Amazon MSKサーバーレスは実際にはIAMのみをサポートしています。なので非常に役立つと思います。
サーバーレスモードを使用するとユーザー名やパスワードを心配する必要はありません。




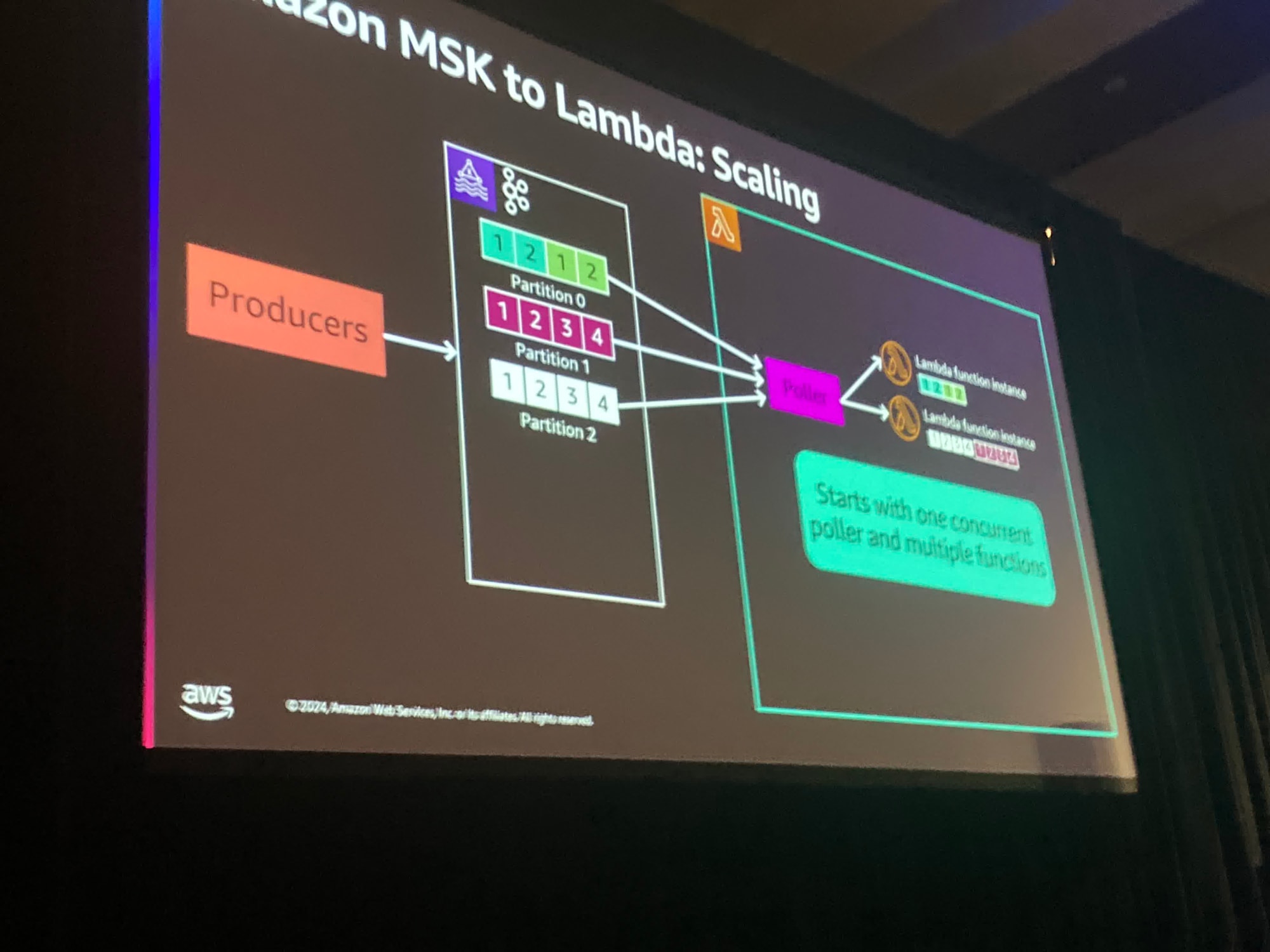
どのようにLambdaがスケールするかについて話しましょう.
ここでは複数のパーティションに対して1つのLambda関数を割り当てます。
これはトピック内のすべてのメッセージが処理できるためです。

徐々にメッセージが増えていくと、パーティション内の順序によって処理を行うために、複数のLambda関数を利用することができます。
したがって、Lambdaは作業負荷に基づいて自動的にコンシューマーの数を増減できるようになります。この管理を行う必要はなく、基本的には毎分ごとにすべてのパーティションに対するコンシューマーオフセットを監視することです。
遅延が高すぎる場合に判断を下します。これはLambda関数の処理が追いついていないことを意味します。
Lambda関数が追加される際には自動的にポーラーが追加され、その後Lambda関数をスケールアウトします。このプロセスには最大で3分かかる場合があります
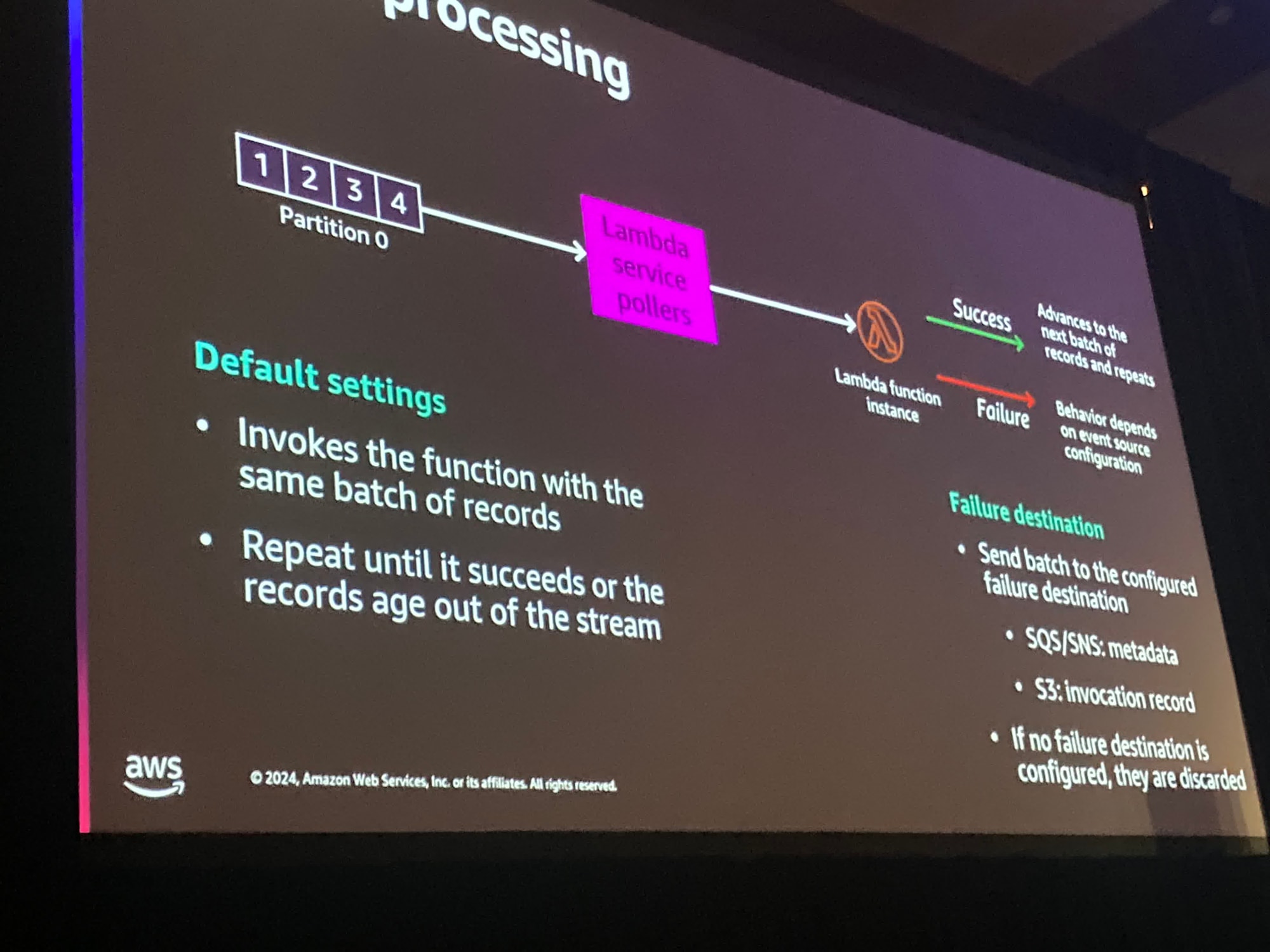
もし処理に成功しなかった場合、リトライのエラー処理はイベントソースマッピングの構成に依存します。
基本的には同じレコードのバッチを使用して再度実行します。そしてバッチが成功するまでこの作業を続けます。
すべてのレコードは、ストレージまたは時間に基づいてストリームから消えていきます。
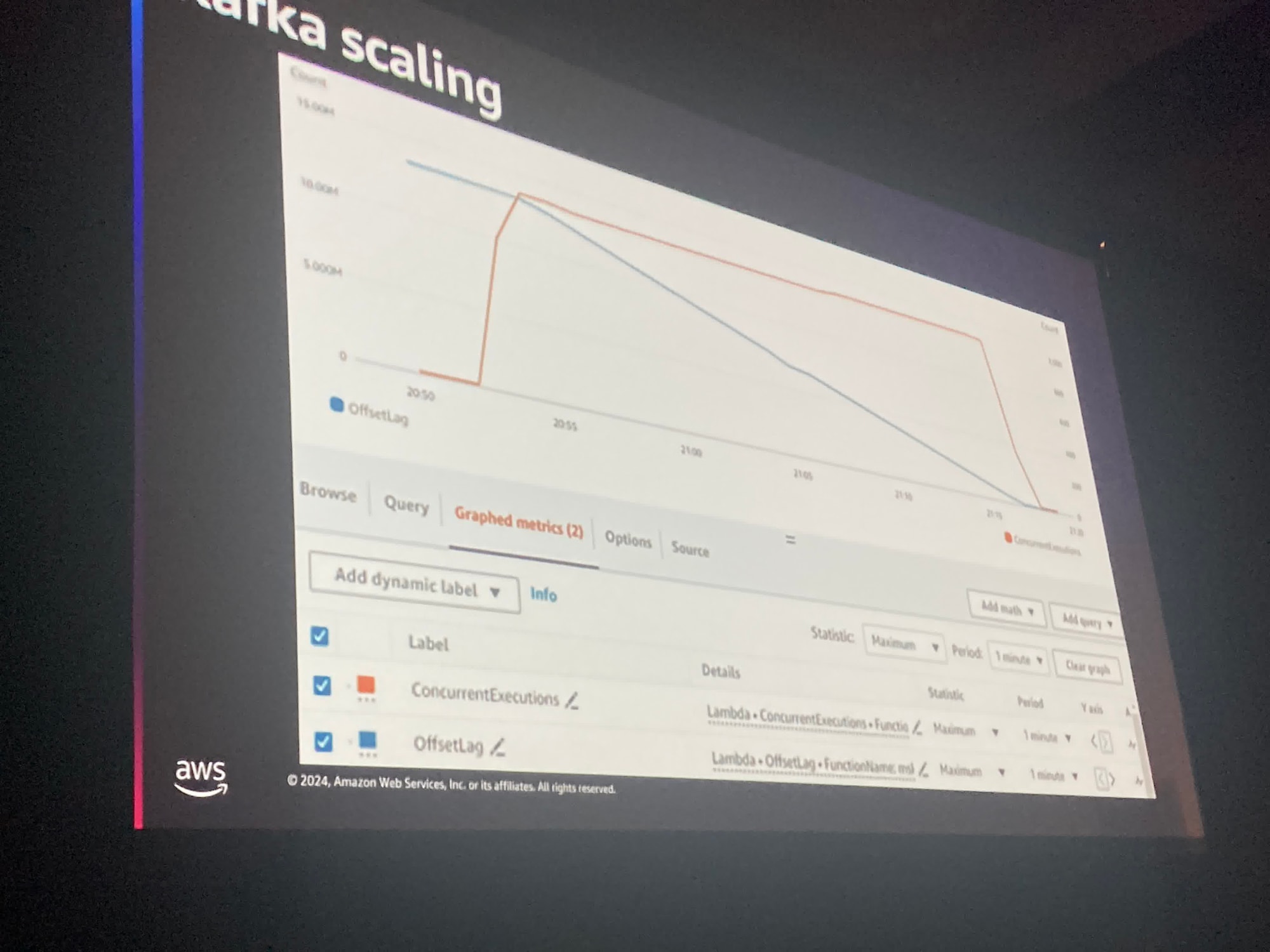
最近KafkaとLambda関数のスケーリングがより高速になりました。
青い線はカスケードクラスタに現多数のメッセージがあります。
そしてオレンジ色の線の上でLambdaが同時実効性をスケールアップしていくことがわかります。
並行呼び出しの数は非常に迅速にできるだけ早く増やされ、なおかつ同時実効性を維持しできるだけ早くメッセージがなくなるようにします。

プロビジョンドモードは2つの異なる設定ができます。

運用で考慮すべき2つの異なる部分があります。
1つはベースラインを理解し、通常のアプリケーションで何が起こっているかを理解することです。
通常の時間の間にどれだけのレコードが到着するのかを把握し、そのレコードサイズがどのぐらいであるかを知りたいです。

また、何かが変わった場合、あなたのメトリクスがどのように進行しているかに深く関係します。
それが何であるかが重要です。処理側のレコード数の増加なのか、サイズの増加なのか、何が変わりましたか?
これは実際に発生してみないと理解できません。
あらかじめ基礎を理解しておください。

Kafka側のMSKは自動的にCloudWatchに統合されており、また、あなた自身でホストしているKafkaでもプッシュすることができます。
そのことに気づいていない人もいます



所感
- Apache kafka自体は知っていたもののまともに触ったことない状態でセッションを聞きましたが、なかなかついていくのが難しかったです。。
- Kafkaをマネージドに使えるのはコスト的にも当てはまる場合が多そうですし、バックエンドにLambdaがいることでより柔軟にConsumerを設定できるのは魅力的だなと感じました。









